Architecture Overview¶
Philosophy¶
Meterplex follows the modular monolith pattern - a single deployable NestJS application with strict module boundaries enforced by the framework's dependency injection system.
Why not microservices?¶
Microservices on day one create a distributed monolith - the worst of both worlds. You get the operational complexity of multiple services (separate deployments, inter-service communication, distributed tracing) without the benefits (independent scaling, isolated failures), because the domain boundaries haven't been proven yet.
The modular monolith gives us:
- One deployment - simpler CI/CD, one Docker image, one health check
- In-process calls - no network latency between modules, no serialization overhead
- Shared database - transactions span modules, no eventual consistency headaches
- Clean extraction path - when a module needs independent scaling, extract it. Kafka topics are already in place for async communication
When to extract a microservice¶
A module becomes a microservice candidate when:
- It needs to scale independently (usage ingestion handles 100x more load than billing)
- It has a different deployment cadence (billing changes weekly, usage is stable)
- It requires a different runtime (ML scoring in Python, not TypeScript)
Until then, modules stay in the monolith.
Module Dependency Rules¶
AppModule
├── ConfigModule (global) - env validation, ConfigService
├── PrismaModule (global) - database access
├── HealthModule - /health endpoint
└── Feature Modules
├── TenantsModule - tenant CRUD
├── UsageModule - usage event ingestion
├── BillingModule - invoice generation
└── ...
Rules:
- Feature modules may depend on
ConfigModuleandPrismaModule(global) - Feature modules communicate through exported services, not internal imports
- No circular dependencies between feature modules
- If Module A needs data from Module B, Module B exports a service that Module A imports
Data Flow¶
Client Request
│
▼
Middleware (correlation ID → request logging)
│
▼
Guards (authentication, authorization)
│
▼
Pipes (validation, transformation)
│
▼
Controller (route handling)
│
▼
Service (business logic)
│
├──▶ PrismaService (database)
├──▶ KafkaProducer (async events)
└──▶ Redis (cache/rate limit)
│
▼
Interceptor (response serialization)
│
▼
Exception Filter (error formatting)
│
▼
Client Response
Infrastructure¶
Meterplex follows a "Performance-First" infrastructure philosophy. For local development, we use Docker Compose with several high-efficiency strategies:
| Service | Container | Port | Purpose |
|---|---|---|---|
| PostgreSQL 18 | meterplex-postgres |
5432 | Primary data store |
| Apache Kafka 4.2 | meterplex-kafka |
9092 | Event streaming (KRaft Mode) |
| Redis 8 | meterplex-redis |
6379 | Cache and rate limiting |
| Kafka UI | meterplex-kafka-ui |
9000 | Debug interface (Dormant by default) |
Key Infrastructure Principles¶
- KRaft Native: We use Kafka 4.2+ in KRaft mode. This eliminates the Zookeeper dependency, reducing the local footprint and speeding up startup times.
- "Zero-Tax" Tooling: High-resource tools like Kafka UI are moved to a Docker Profile (
debug). They consume 0% CPU by default and are only started when explicitly requested viapnpm docker:ui. - Isolated Networking: All containers communicate over a dedicated
meterplex-internalbridge network. This provides faster DNS resolution and ensures the infrastructure is isolated from other projects running on the host. - Hardware-Native: We prioritize Alpine-based images and native ARM64 support to ensure 100% performance on modern silicon (Apple M-series).
In production, these services are typically replaced by cloud-native managed solutions (e.g., AWS RDS, MSK, and ElastiCache).
Phase 1 - Data model¶
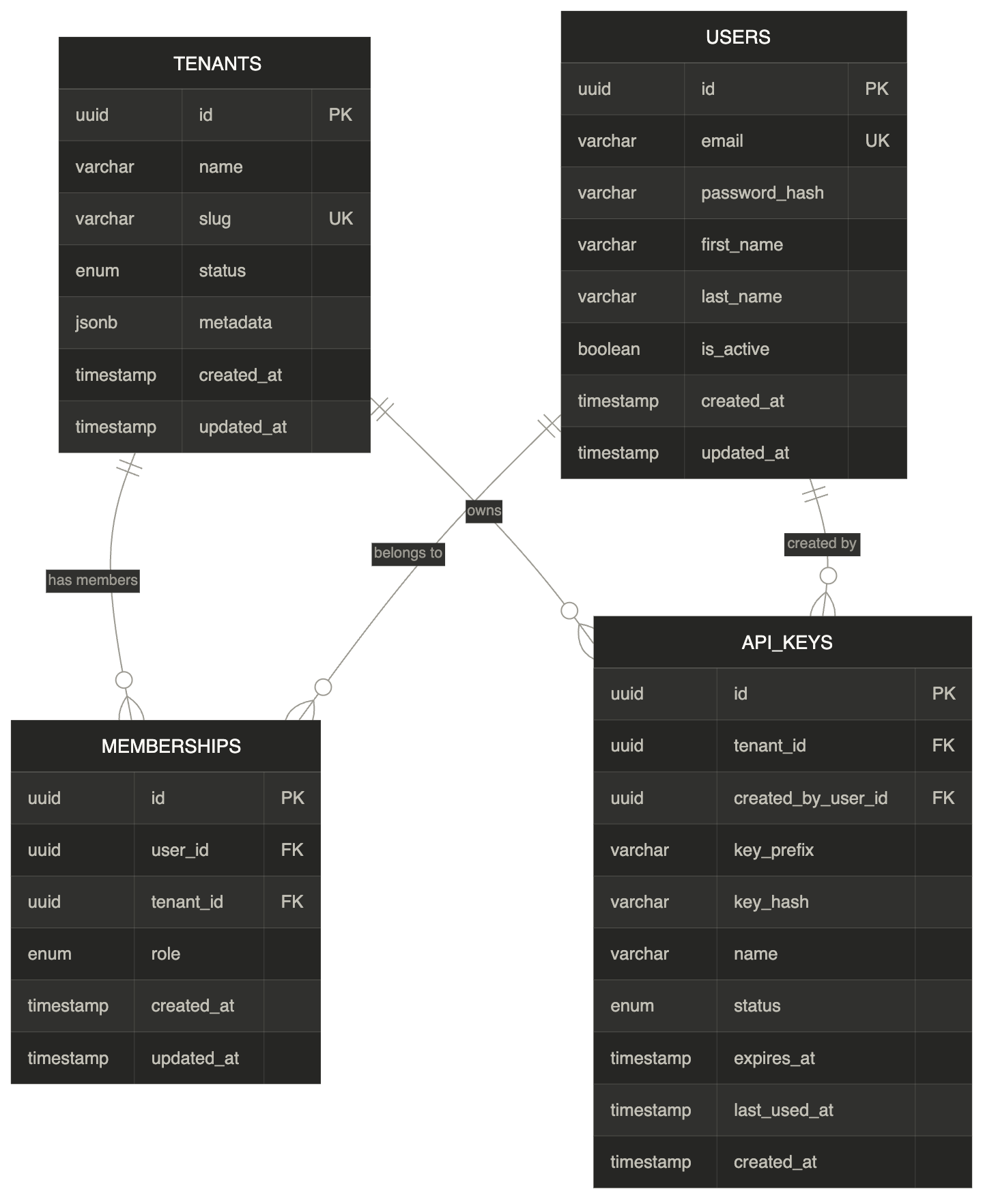
Four tables: tenants (organizations), users (global accounts), memberships (join table with roles), and api_keys (server-to-server authentication). A user can belong to multiple tenants with different roles via the memberships table.
Phase 2 - Plans & Entitlements¶
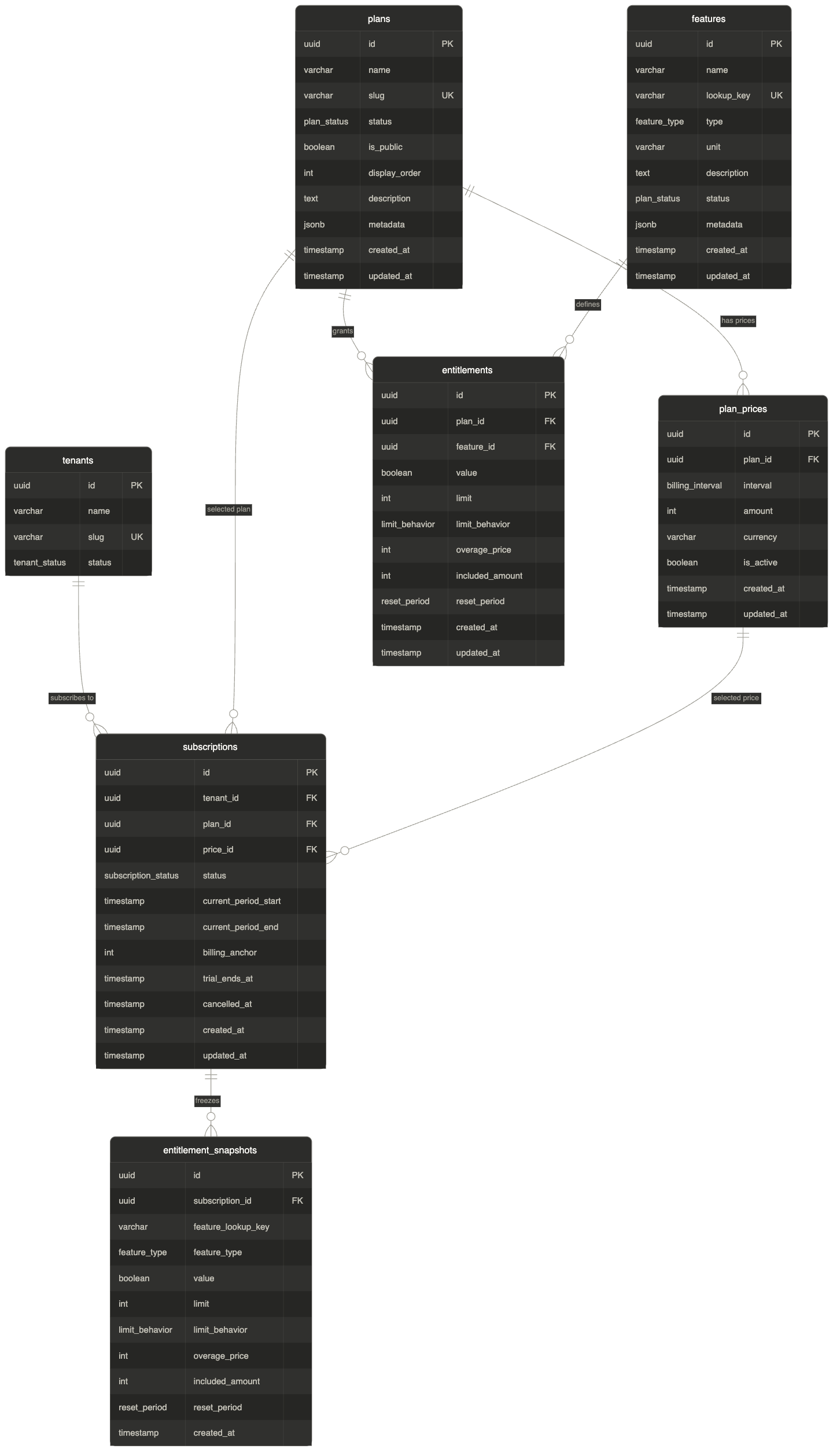
Phase 2 adds plans, pricing, features, entitlements, subscriptions, and entitlement snapshots to define access rules and map customer organizations to subscription tiers.
Phase 3 - Usage Ingestion & Kafka Pipeline¶
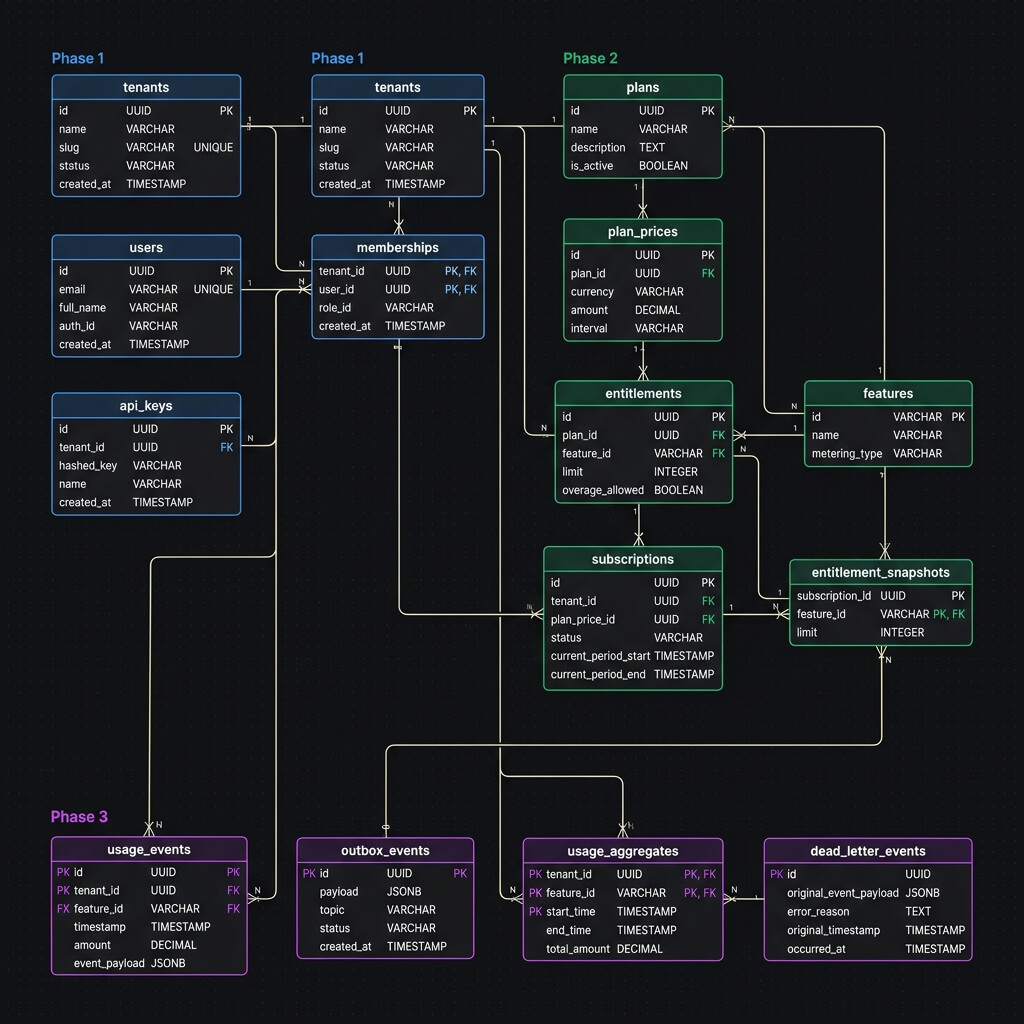
Phase 3 introduces four new tables to support transactional event ingestion, outbox-driven Kafka publishing, high-performance counting, and robust error/dead-letter auditing:
usage_events: Immutable event log of raw submissions.outbox_events: Transactional outbox for guaranteed Kafka publishing.usage_aggregates: Rolled-up counters per tenant, feature, and billing period (cached in Redis).dead_letter_events: Operational record for failed events requiring administrative triage.